

为MySQL数据库集群部署MHA高可用
什么是MHA MHA(Master High Availability)是用于提高数据库集群可用性的方案,基于虚拟IP技术,可以实现在Master故障时,在30s内实现故障转移并确保数据一致性。可以理解为MHA就是作用于数据库集群的KeepAlived。 MHA工作原理 MHA的组成 MHA由MHA Manager和MHA Node组成,其中Manager相当于服务端,Node相当于客户端; Manager可以部署在Master或Slave机器上,也可以单独的部署在一台机器上;一般建议部署在一台单独的机器上,因为Manager是用于探测数据库实例是否在线和进行故障转移的核心程序,如果部署在Master上,一旦Master机器报销,整个数据库集群的不再可以;另外,如果部署在Slave机器上,那么这台机器就不能够被提升为Master。 Node需要部署在所有MySQL数据库实例的机器上。 MHA故障转移流程 * Manager会每隔一段时间(可以由用户在配置文件中指定)对主库进行一次探测; * 如果Manager检测到Master故障,会执行
什么是MHA
MHA(Master High Availability)是用于提高数据库集群可用性的方案,基于虚拟IP技术,可以实现在Master故障时,在30s内实现故障转移并确保数据一致性。可以理解为MHA就是作用于数据库集群的KeepAlived。
MHA工作原理
MHA的组成
MHA由MHA Manager和MHA Node组成,其中Manager相当于服务端,Node相当于客户端;
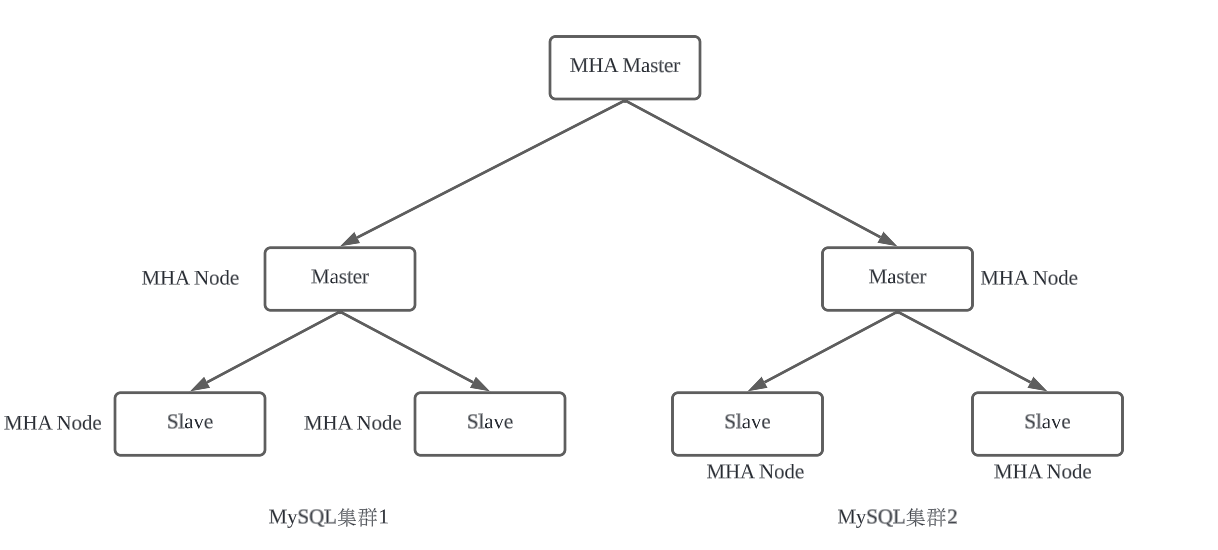
Manager可以部署在Master或Slave机器上,也可以单独的部署在一台机器上;一般建议部署在一台单独的机器上,因为Manager是用于探测数据库实例是否在线和进行故障转移的核心程序,如果部署在Master上,一旦Master机器报销,整个数据库集群的不再可以;另外,如果部署在Slave机器上,那么这台机器就不能够被提升为Master。
Node需要部署在所有MySQL数据库实例的机器上。
MHA故障转移流程
部署MHA
环境准备
使用三台机器,其中MySQL一主一从,Manager单独布置在一台管理机器上。
配置文件
除了server_id其他都一样
配置主从复制
创建复制账号
从库进行连接
使三个节点之间互相免密登录:
安装MHA
为所有节点安装环境依赖
三个节点都安装MHA Node
MHA Node Github仓库
安装MHA Manager
MHA Manager Github仓库
这里由于只用了两台机器,因此Manager必须装在另外单独的一台主机上,否则对于一主一从配置来说,装在主库上,挂掉后会导致MHA失效;装在从库上,会导致无法提升为主库;
配置MHA
为所有节点创建MHA用户
因为目前已经配置好了主从复制,所以在主库上创建就可以了,会自动同步到从库。
创建MHA Manager配置文件
创建目录
配置文件
检查环境配置
开发Virtual IP漂移脚本
脚本路径:
/usr/local/bin/master_ip_failover增加可执行权限:
将脚本路径加入到配置文件中:
master_ip_failover_script=/usr/local/bin/master_ip_failover配置虚拟IP
在db-51机器上创建虚拟IP
重启MHA
此时MHA就已经部署完毕了。
模拟故障
实时查看manager日志:
停止当前mysql主库
此时查看日志,可以发现manager尝试多次连接mysql主库失败,manager进行了主库身份转移。
结果报告:
在完成故障转移后,可以看到现在的master是db-52;同时,manager还修改了自己的配置文件,挂掉的原master被删除
除此之外,通过
masterha_check_status命令还可以知道,一旦mha完成主从切换,manager管理进程就会自动终止。MHA故障修复
方法比较简单
CHANGE MASTER TO使其成为新的主库的从库。db-51重新加入主从复制
可以在db-52上进行确认:
修复MHA Manager配置文件
再次确认ssh链接和repl主从复制状态后,重新启动MHA就可以了。
Read Next
MySQL/Redis相关面试题
数据库运维(MySQL和Redis)的面试题总结
事件源模式和传统数据库方法在数据管理上的优劣分析
对事件源模式和传统数据库方法在应用程序性能影响、性能、扩展性和可靠性的分析;以及云原生环境下数据管理的最佳实践
关于Metrics_server在自托管环境下无法使用的问题
修复kubernetes的metrics server在自托管环境下因缺少CA证书而无法运行的问题。
关于IP、子网掩码、主机位和网络位的计算方法
如何通过子网掩码和掩码位计算一个IP地址的网络地址和可分配的主机位